晚上朋友告诉我数据库不能open,请求技术支持,检查alert日志发现ORA-00600[kccpb_sanity_check_2]错误导致数据库无法正常mount
Fri Jun 6 23:36:08 2014 alter database mount Fri Jun 6 23:36:08 2014 This instance was first to mount Fri Jun 6 23:36:12 2014 Errors in file /on3000/oracle/admin/on3000/udump/on30001_ora_295198.trc: ORA-00600:内部错误代码, 参数:[kccpb_sanity_check_2], [18045], [17928], [0x000000000], [], [], [], [] ORA-600 signalled during: alter database mount...
依次替换三个控制文件依然无法解决该问题。查询MOS得到解释为[435436.1]
ORA-600 [kccpb_sanity_check_2] indicates that the seq# of the last read block is higher than the seq# of the control file header block. This is indication of the lost write of the header block during commit of the previous cf transaction.
出现该故障的原因是因为写丢失导致,而解决该故障的方法有
1) restore a backup of a controlfile and recover OR 2) recreate the controlfile OR 3) restore the database from last good backup and recover
该数据库为无备份非归档数据库,因此只能重建控制文件来解决ORA-00600[kccpb_sanity_check_2]故障,通过重建控制文件数据库mount成功.但是在open的过程中又出现需要一个不存在的归档日志(数据库一个节点5月5日异常,另外一个节点5月23日异常,到6月6日我接手中间进行了N多操作,未细细分析原因).
Oracle Database Recovery Check Result检查结果
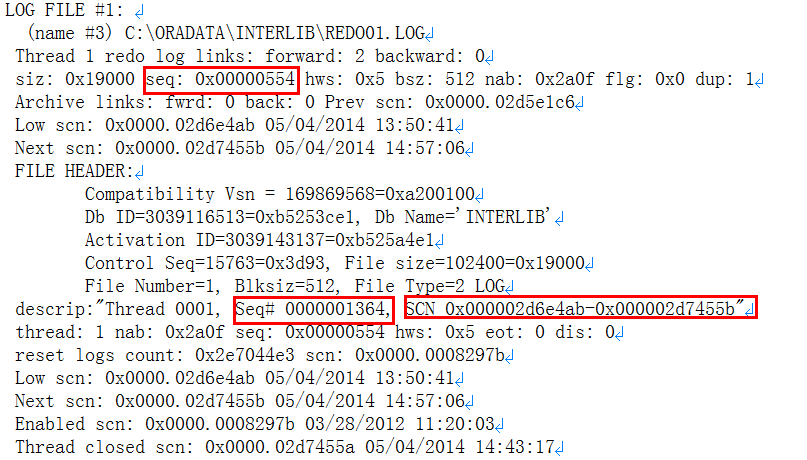
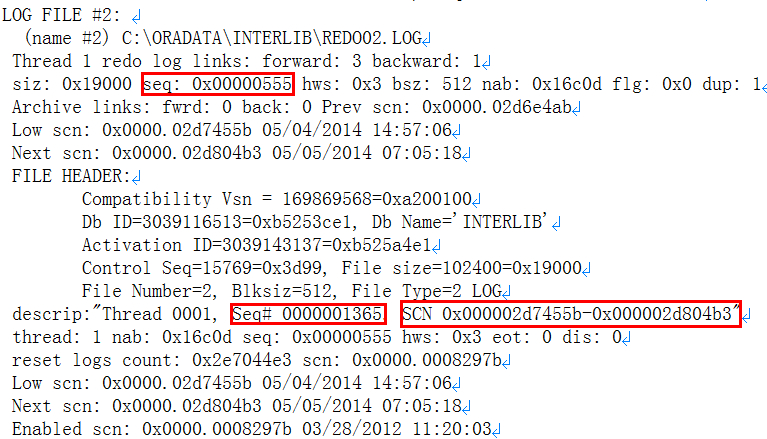
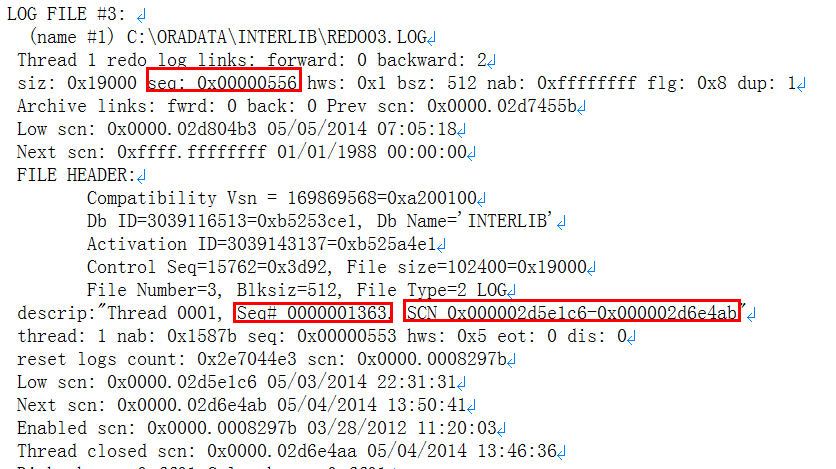
数据库SCN

控制文件中关于数据文件SCN
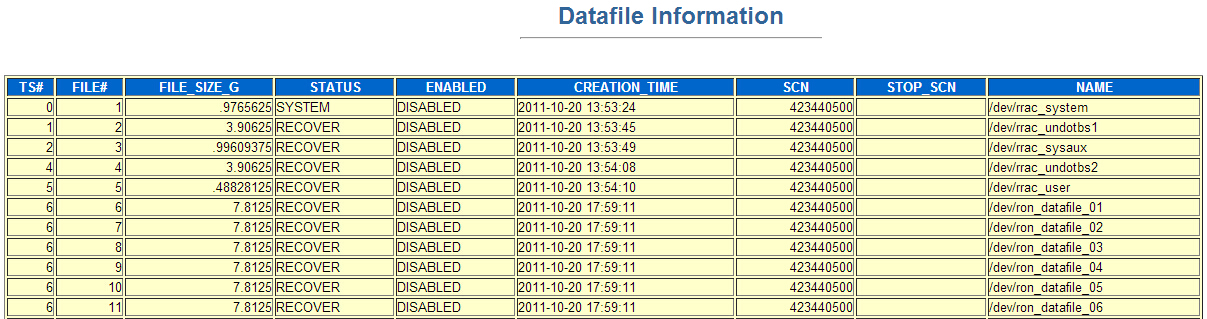
数据文件头SCN
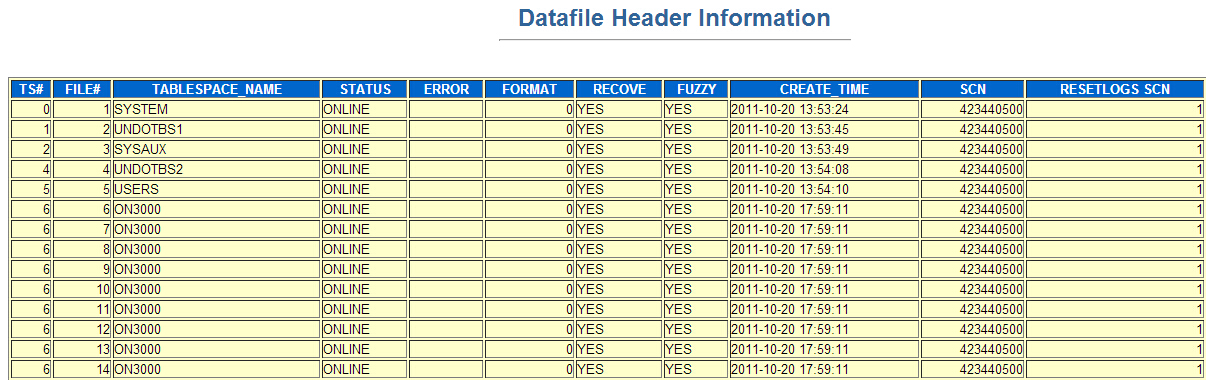
REDO SCN

这里明显表示thread#缺少归档,导致恢复过程出现如下提示
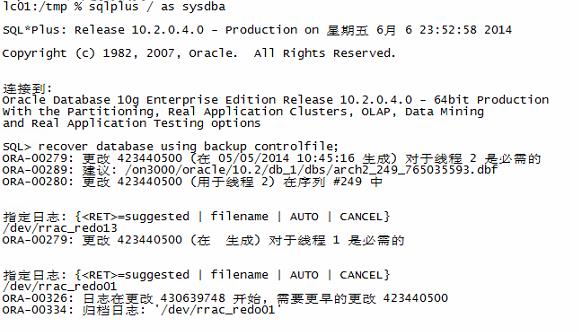
最后没有办法只能使用_allow_resetlogs_corruption参数跳过redo,然后去open数据库,很不幸出现更加悲催的ORA-00704和ORA-00600[kcbgtcr_13]错误,导致数据库open失败
Sat Jun 7 00:28:58 2014 SMON: enabling cache recovery Sat Jun 7 00:28:58 2014 Errors in file /on3000/oracle/admin/on3000/udump/on30001_ora_344084.trc: ORA-00600: 内部错误代码, 参数: [kcbgtcr_13], [], [], [], [], [], [], [] Sat Jun 7 00:28:59 2014 Errors in file /on3000/oracle/admin/on3000/udump/on30001_ora_344084.trc: ORA-00704: 引导程序进程失败 ORA-00704: 引导程序进程失败 ORA-00600: 内部错误代码, 参数: [kcbgtcr_13], [], [], [], [], [], [], [] Sat Jun 7 00:28:59 2014 Error 704 happened during db open, shutting down database USER: terminating instance due to error 704 Instance terminated by USER, pid = 344084 ORA-1092 signalled during: alter database open...
对启动过程做10046发现
*** 2014-06-07 00:28:58.528
ksedmp: internal or fatal error
ORA-00600: 内部错误代码, 参数: [kcbgtcr_13], [], [], [], [], [], [], []
Current SQL statement for this session:
select ctime, mtime, stime from obj$ where obj# = :1
----- Call Stack Trace -----
calling call entry argument values in hex
location type point (? means dubious value)
-------------------- -------- -------------------- ----------------------------
ksedst+001c bl ksedst1 000000004 ? 10538629C ?
ksedmp+0290 bl ksedst 104A2CDB0 ?
ksfdmp+0018 bl 03F2735C
kgerinv+00dc bl _ptrgl
kgeasnmierr+004c bl kgerinv 000000000 ? 10564B4CC ?
000000004 ? 70000006D3FD6F0 ?
000000000 ?
kcbassertbd+0074 bl kgeasnmierr 110195490 ? 110486310 ?
10564BD54 ? 000000000 ?
000000000 ? 000000000 ?
000000000 ? 11043DC90 ?
kcbgtcr+2a68 bl kcbassertbd FFFFFFFFFFE7D00 ?
FFFFFFFFFE7D28 ?
kturbk1+0258 bl kcbgtcr 000000000 ? 104D23384 ?
104D2330C ? 000000000 ?
ktrgcm+1294 bl kturbk1 F0000000F ? FFFFFFFFFFE84B8 ?
000000000 ? 000000000 ?
FFFFFFFFFFE84D0 ? 000000000 ?
ktrgtc+0660 bl ktrgcm 1104B7600 ?
kdsgrp+0094 bl ktrgtc 0000006C8 ? 000000000 ?
FFFFFFFFFFE8D80 ?
28242043335E5162 ?
103A06D48 ? 70000006F6C87B8 ?
1051C3528 ?
kdsfbrcb+0298 bl kdsgrp 1044726E4 ?
433000000000003B ?
FFFFFFFFFFE8E30 ?
qertbFetchByRowID+0 bl 03F27E18
69c
qerstFetch+00ec bl 01F9482C
opifch2+141c bl 03F25E6C
opifch+003c bl opifch2 FFFFFFFFFFEC3D8 ? 000000000 ?
FFFFFFFFFFEA360 ?
opiodr+0ae0 bl _ptrgl
rpidrus+01bc bl opiodr 5FFFEC840 ? 200000000 ?
FFFFFFFFFFEC850 ? 500000000 ?
skgmstack+00c8 bl _ptrgl
rpidru+0088 bl skgmstack 11049A820 ? 110195490 ?
000000002 ? 000000000 ?
FFFFFFFFFFEC3E8 ?
rpiswu2+034c bl _ptrgl
rpidrv+095c bl rpiswu2 70000006F6C7250 ? 1104851E8 ?
000000000 ? 000000000 ?
000000000 ? 000000000 ?
1101B8C48 ? 000000000 ?
rpifch+0050 bl rpidrv 5FFFEC840 ? 500000000 ?
FFFFFFFFFFEC850 ? 06CD75F70 ?
kqdpts+0134 bl rpifch 11022A3E0 ?
kqrlfc+0258 bl kqdpts 000000000 ?
kqlbplc+00b4 bl 03F28AF0
kqlblfc+0204 bl kqlbplc 10011A9A8 ?
adbdrv+1978 bl 01F944B4
opiexe+2c08 bl adbdrv
opiosq0+19f0 bl opiexe FFFFFFFFFFF9550 ? 100000000 ?
FFFFFFFFFFF8F20 ?
kpooprx+0168 bl opiosq0 3693644A8 ? 700000010003520 ?
700000069364428 ?
A4000110195490 ?
kpoal8+0400 bl kpooprx FFFFFFFFFFFB774 ?
FFFFFFFFFFFB500 ?
1B0000001B ? 100000001 ?
000000000 ? A40000000000A4 ?
000000000 ? 11039FA18 ?
opiodr+0ae0 bl _ptrgl
ttcpip+1020 bl _ptrgl
opitsk+1124 bl 01F971E8
opiino+0990 bl opitsk 1E00000000 ? 000000000 ?
opiodr+0ae0 bl _ptrgl
opidrv+0484 bl 01F96034
sou2o+0090 bl opidrv 3C02D9A29C ? 4A006E298 ?
FFFFFFFFFFFF6B0 ?
opimai_real+01bc bl 01F939B4
main+0098 bl opimai_real 000000000 ? 000000000 ?
__start+0070 bl main 000000000 ? 000000000 ?
--------------------- Binary Stack Dump ---------------------
--undo cr构造记录
Dump of buffer cache at level 1 for tsn=4, rdba=16777293
BH (700000035fb77b8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000357b4000
set: 10 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035f969c8,70000006d3fd868] lru: [700000035fb7728,70000006d6acff0]
ckptq: [NULL] fileq: [NULL] objq: [700000035fb7798,7000000693932c0]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5fb],[sfl: 0x0]
flags:
BH (700000035f969c8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000353d6000
set: 9 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035ff9398,700000035fb77b8] lru: [700000035f96938,70000006d6aca98]
ckptq: [NULL] fileq: [NULL] objq: [700000035f969a8,700000069390250]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5fa],[sfl: 0x0]
flags:
BH (700000035ff9398) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 700000035f70000
set: 12 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035fd86b8,700000035f969c8] lru: [700000035ff9528,70000006d6adaa0]
ckptq: [NULL] fileq: [NULL] objq: [7000000693973c8,7000000693973c8]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5f9],[sfl: 0x0]
flags:
BH (700000035fd86b8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 700000035b94000
set: 11 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035fb76a8,700000035ff9398] lru: [700000035fd8848,70000006d6ad548]
ckptq: [NULL] fileq: [NULL] objq: [700000069396398,700000069396398]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5f8],[sfl: 0x0]
flags:
BH (700000035fb76a8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000357b2000
set: 10 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035f968b8,700000035fd86b8] lru: [700000035fb7948,700000035fb7838]
ckptq: [NULL] fileq: [NULL] objq: [7000000693932c0,700000035fb78a8]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5f7],[sfl: 0x0]
flags:
BH (700000035f968b8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000353d4000
set: 9 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [70000006d3fd868,700000035fb76a8] lru: [700000035f96b58,700000035f96a48]
ckptq: [NULL] fileq: [NULL] objq: [700000069390250,700000035f96ab8]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5f6],[sfl: 0x0]
flags:
WAIT #5: nam='db file sequential read' ela= 135 file#=4 block#=77 blocks=1 obj#=-1 tim=1107709395109
on-disk scn: 0x0.19af5d47
BH (700000035fb77b8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000357b4000
set: 10 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035f969c8,70000006d3fd868] lru: [700000035fb7728,70000006d6acff0]
ckptq: [NULL] fileq: [NULL] objq: [700000035fb7798,7000000693932c0]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5fb],[sfl: 0x0]
flags:
Dump of buffer cache at level 10 for tsn=4, rdba=16777293
BH (700000035fb77b8) file#: 4 rdba: 0x0100004d (4/77) class: 46 ba: 7000000357b4000
set: 10 blksize: 8192 bsi: 0 set-flg: 2 pwbcnt: 0
dbwrid: 0 obj: -1 objn: 0 tsn: 4 afn: 4
hash: [700000035f969c8,70000006d3fd868] lru: [700000035fb7728,70000006d6acff0]
ckptq: [NULL] fileq: [NULL] objq: [700000035fb7798,7000000693932c0]
st: CR md: NULL tch: 0
cr: [scn: 0x0.1],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x0.19afb5fb],[sfl: 0x0]
flags:
buffer tsn: 4 rdba: 0x0100004d (4/77)
scn: 0x0000.19af5d47 seq: 0x01 flg: 0x04 tail: 0x5d470201
frmt: 0x02 chkval: 0x6d2e type: 0x02=KTU UNDO BLOCK
--obj$ block dump记录
Block header dump: 0x0040007a
Object id on Block? Y
seg/obj: 0x12 csc: 0x00.19afb597 itc: 1 flg: - typ: 1 - DATA
fsl: 0 fnx: 0x0 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000f.012.0002c79c 0x0100004d.6113.1c --U- 1 fsc 0x0000.19afb598
这里可以知道,数据库在读取obj$的时候使用到了undo cr块的构造,由于某种原因导致构造cr块失败,从而出现ORA-00600[kcbgtcr_13]错误,而因为obj$又在bootstarp$里面,因此又出现ORA-704.所以解决该问题的方法就是让数据库在查询obj$表的时候不再进行cr块构造,比如使用bbed提交事务等方法解决.这里使用bbed提交事务(bbed模拟提交事务一之修改itl),数据库启动成功
SQL> startup ORACLE 例程已经启动。 Total System Global Area 1610612736 bytes Fixed Size 2084400 bytes Variable Size 973078992 bytes Database Buffers 620756992 bytes Redo Buffers 14692352 bytes 数据库装载完毕。 数据库已经打开。