
UNDO异常报错千奇百怪,针对本人遇到的比较常见的undo异常报错进行汇总,仅供参考,数据库恢复过程是千奇百怪的,不能照搬硬套.
ORA-00704/ORA-00376
ORA-00704: bootstrap process failure
ORA-00604: error occurred at recursive SQL level 2
ORA-00376: file 3 cannot be read at this time
ORA-01110: data file 3: ‘/u01/oracle/oradata/ora11g/undotbs01.dbf’
Error 704 happened during db open, shutting down database
USER (ospid: 17864): terminating the instance due to error 704
Instance terminated by USER, pid = 17864
ORA-1092 signalled during: alter database open…
opiodr aborting process unknown ospid (17864) as a result of ORA-1092
ORA-00600[4097]
Fri Aug 31 23:14:10 2012
Errors in file /u01/oradata/orcl/bdump/orcl_smon_15589.trc:
ORA-00600: internal error code, arguments: [4097], [], [], [], [], [], [], []
Fri Aug 31 23:14:12 2012
Non-fatal internal error happenned while SMON was doing logging scn->time mapping.
SMON encountered 1 out of maximum 100 non-fatal internal errors.
ORA-01595/ORA-00600[4194]
Fri Aug 31 23:14:14 2012
Errors in file /u01/oradata/orcl/bdump/orcl_smon_15589.trc:
ORA-01595: error freeing extent (2) of rollback segment (4))
ORA-00607: Internal error occurred while making a change to a data block
ORA-00600: internal error code, arguments: [4194], [48], [34], [], [], [], [], []
0RA-00600[4193]
Tue Feb 14 09:35:34 2012
Errors in file d:\oracle\product\10.2.0\admin\interlib\udump\interlib_ora_2824.trc:
ORA-00603: ORACLE server session terminated by fatal error
ORA-00600: internal error code, arguments: [4193], [2005], [2008], [], [], [], [], []
ORA-00600[kcfrbd_3]
Wed Dec 05 10:26:35 2012
SMON: enabling tx recovery
Wed Dec 05 10:26:35 2012
Database Characterset is ZHS16GBK
Wed Dec 05 10:26:35 2012
Errors in file d:\oracle\product\10.2.0\admin\orcl\bdump\orcl_smon_548.trc:
ORA-00600: internal error code, arguments: [kcfrbd_3], [2], [2279045], [1], [2277120], [2277120], [], []
SMON: terminating instance due to error 474
ORA-00600[4137]
Fri Jul 6 18:00:40 2012
SMON: ignoring slave err,downgrading to serial rollback
Fri Jul 6 18:00:41 2012
Errors in file /usr/local/oracle/admin/techdb/bdump/techdb_smon_16636.trc:
ORA-00600: internal error code, arguments: [4137], [], [], [], [], [], [], []
ORACLE Instance techdb (pid = 8) – Error 600 encountered while recovering transaction (3, 17).
ORA-01595/ORA-01594
Sat May 12 21:54:17 2012
Errors in file /oracle/app/admin/prmdb/bdump/prmdb2_smon_483522.trc:
ORA-01595: error freeing extent (2) of rollback segment (19))
ORA-01594: attempt to wrap into rollback segment (19) extent (2) which is being freed
ORA-00704/ORA-01555
Fri May 4 21:04:21 2012
select ctime, mtime, stime from obj$ where obj# = :1
Fri May 4 21:04:21 2012
Errors in file /oracle/admin/standdb/udump/perfdb_ora_1286288.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00604: error occurred at recursive SQL level 1
ORA-01555: snapshot too old: rollback segment number 40 with name “_SYSSMU40$” too small
Error 704 happened during db open, shutting down database
USER: terminating instance due to error 704
Instance terminated by USER, pid = 1286288
ORA-1092 signalled during: alter database open resetlogs…
ORA-00607/ORA-00600[4194]
Block recovery completed at rba 3994.5.16, scn 0.89979533
Thu Jul 26 13:21:11 2012
Errors in file /orasvr/admin/mispdata/udump/mispdata_ora_2865.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-00607: Internal error occurred while making a change to a data block
ORA-00600: internal error code, arguments: [4194], [31], [2], [], [], [], [], []
Error 604 happened during db open, shutting down database
USER: terminating instance due to error 604
Instance terminated by USER, pid = 2865
ORA-1092 signalled during: ALTER DATABASE OPEN…
ORA-00704/ORA-00600[4000]
Thu Feb 28 19:29:13 2013
Errors in file /u1/PROD/prodora/db/tech_st/10.2.0/admin/PROD_oracle/udump/prod_ora_20989.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [4000], [50], [], [], [], [], [], []
Thu Feb 28 19:29:13 2013
Error 704 happened during db open, shutting down database
USER: terminating instance due to error 704
Instance terminated by USER, pid = 20989
ORA-1092 signalled during: ALTER DATABASE OPEN RESETLOGS…
undo异常恢复处理思路
除了极少数undo坏块,undo文件丢失外,大部分undo异常是因为redo未被正常进行前滚,从而导致undo回滚异常数据库无法open,解决此类问题,需要结合一般需要结合redo异常处理技巧在其中,一般undo异常处理思路
1.切换undo_management= MANUAL尝试启动数据库,如果不成功进入2
2.设置10513 等event尝试启动数据库,如果不成功进入3
3.使用_offline_rollback_segments/_corrupted_rollback_segments屏蔽回滚段
4.如果依然不能open数据库,考虑使用bbed工具提交事务,修改回滚段状态等操作
5.如果依然还不能open数据库,考虑使用dul
如果您按照上述步骤还不能解决,请联系我们,将为您提供专业数据库技术支持
Phone:17813235971 Q Q:107644445 E-Mail:dba@xifenfei.com
姊妹篇
ORACLE REDO各种异常恢复
ORACLE丢失各种文件导致数据库不能OPEN恢复
Category Archives: Oracle
ORACLE 12C RAC主要gc等待事件
ORACLE 12C RAC中有很多GC等待事件,这里重点介绍一些常见的GC等待事件,以便在以后遇到类似问题方便分析
RAC等待事件
在本节中我将讨论重要的RAC等待事件。这还不是全部等待事件的完整列表,只是一个最常见的等待事件的列表。
GC当前块2-Way/3-Way
当前块的等待事件意味着被传输的块的版本是块的最新版本。这个等待事件读取和写入活动中都可能遇到。如果该块被访问是以读取活动进行,那么该资源上锁以KJUSERPR(PR)模式获得。刚才我在“资源和锁定”一节中所讨论的示例展示了KJUSERPR模式的锁。
在下面的例子中,我从表t_one中查询一行,造成连接到节点2的磁盘读。查看SQL跟踪文件,没有全局缓存等待事件。原因是该块被本地掌控(本地实例是master),所以FG进程中可直接获取该资源上锁,而不会产生任何全局缓存等待。这种类型的锁也被称为亲和力锁定(相似度锁定)方案。动态掌握资源(DRM,Dynamic Resource Mastering)的部分将详细讨论相似度锁定(亲和力锁定)。
RS@ORCL2:2> @tc_one_row.sql
N1 FNO BLOCK OBJ V1
———- ———- ———- ———- ———-
100 4 180 75742 250
Trace file:
nam=’db file sequential read’ ela= 563 file#=4 block#=180 blocks=1 obj#=75742
我连接到实例1(注释5)查询同一行数据。由于该块已经缓存在实例2,因此该块从实例2传输到实例1。跟踪显示,等待事件gc current block 2-way由于file_id=4,BLOCK_ID=180块而被遇到了。这个块传输是一个两路的块传输,因为该资源的拥有实例和资源主实例(实例2)是相同的。
SYS@ORCL1:1> @tc_one_row.sql
N1 FNO BLOCK OBJ V1
———- ———- ———- ———- ———-
100 4 180 75742 250
Trace file:
nam=’gc current block 2-way’ ela= 629 p1=4 p2=180 p3=1 obj#=75742 tim=1350440823837572
接下来,我将创建一个3路等待事件的条件,但首先让我在所有三个实例上刷新缓冲区,开始用干净的缓冲区。在以下示例中:
1.我将连接到实例1查询(这将加载块到实例1的缓冲区高速缓存中)这行数据。
2.我将连接到一个实例,并从实例3查询同一行。我会话的FG进程将为这一数据块请求运行在实例2上的LMS进程(因为实例2是该资源的掌控者)。
3.实例2的LMS进程将请求转发给实例1的LMS进程。
4.实例1的LMS进程将发送块给运行在实例3上的FG进程。
从本质上讲,三个实例参与一个数据块的传输,因此,这是一个三路块传输。
–alter system flush buffer_cache; –在所有实例上
RS@ORCL1:1> @tc_one_row.sql
N1 FNO BLOCK OBJ V1
———- ———- ———- ———- ———-
100 4 180 75742 250
RS@ORCL3:3> @tc_one_row.sql
N1 FNO BLOCK OBJ V1
———- ———- ———- ———- ———-
100 4 180 75742 250
Trace file:
nam=’gc current block 3-way’ ela= 798 p1=4 p2=180 p3=1 obj#=75742
连接到实例2查看资源锁,我们看到在该资源上有两个锁被持,分别是实例1和实例3(owner_node等于0和2)。
RS@ORCL2:2> SELECT resource_name1, grant_level, state, owner_node
FROM v$ges_enqueue
WHERE resource_name1 LIKE ‘[0xb4][0x4],[BL]%’;
RESOURCE_NAME1 GRANT_LEV STATE OWNER_NODE
—————————— ——— ————- ———-
[0xb4][0x4],[BL][ext 0x0,0x0] KJUSERPR GRANTED 2
[0xb4][0x4],[BL][ext 0x0,0x0] KJUSERPR GRANTED 0
在gc current block 2-way or gc current block 3-way等待事件上的过多等待,通常要么是由于(a)一种低效的执行计划,导致了大量的块访问,或者(b)应用数据相似度(应用亲和力)没有被实施。如果对象访问本地化,考虑实施应用亲和力(应用数据的相似度)。此外,使用前面一节中讨论的技术“所有等待事件的通用分析”。
GC CR Block 2-Way/3-Way
CR模式的块传输发生在只读访问的请求中。考虑这样一个场景:一个块以CURRENT模式驻留在实例2上,实例2以独占模式保持了该资源的BL锁。另一个会话连接到实例1来请求该块,阻止。由于Oracle数据库中“其他人看不到未提交的更改”,SELECT语句请求一个查询开始时间的块的特定版本。SCN被用于标识块版本,本质上,SELECT语句请求的版本与块的SCN一致。LMS进程维护实例2的请求,以CURRENT的模式克隆该块到缓冲区,验证SCN版本与请求是一致的,然后发送该块的CR拷贝给FG进程。
这些CR模式传输和CURRENT模式传输之间的主要区别在于,在CR模式传输的情况下,在GRD中没有资源或锁来维护CR缓冲区。从本质上讲,CR模式块不需要全局缓存资源或锁。接收到的CR副本只能由提出请求的会话使用,并且只适用于这个特定的SQL执行中。这就是为什么Oracle数据库不对CR传输获取BL资源的任何锁。
由于没有全局缓存锁保护缓冲区,连接到实例1再次执行这个SQL语句访问那个块时将遭遇gc cr block 2-way 或者 gc cr block 3-way等待事件。
因此,每次从实例1访问该块都将触发新CR缓冲区的构造。即使在实例2的缓冲区没有发生该块修改,在实例1中的FG进程仍然会遭遇到CR等待事件。驻留在实例1的CR缓冲区是不能重复使用的,因为每SQL执行请求查询时的SCN会有所不同。
下面的跟踪显示了一个块从资源主实例以0.6毫秒的延迟被传输到请求实例。另外,file_id,BLOCK_ID,和跟踪文件中的object_id信息,可以被用来识别正在遭遇这两个等待事件的对象。当然,也可以通过查询ASH数据来识别该对象。
nam=’gc cr block 2-way’ ela= 627 p1=7 p2=6852 p3=1 obj#=76483 tim=37221074057
执行tc_one_row.sql五次,然后查询缓冲区头信息后,你可以看到在两个实例1和2有五个该块的CR缓冲区。请注意,CR_SCN_BAS和CR_SCN_WRP 列(注释6)显示了每个CR缓冲副本不同的值。查询GV$ ges_resource和GV$ ges_enqueue,你也可以看到有没有GC锁保护这些缓冲区。
清单10-10 缓冲区状态
SELECT
DECODE(state,0,’free’,1,’xcur’,2,’scur’,3,’cr’, 4,’read’,5,’mrec’,
6,’irec’,7,’write’,8,’pi’, 9,’memory’,10,’mwrite’,
11,’donated’, 12,’protected’, 13,’securefile’, 14,’siop’,
15,’recckpt’, 16, ‘flashfree’, 17, ‘flashcur’, 18, ‘flashna’) state,
mode_held, le_addr, dbarfil, dbablk, cr_scn_bas, cr_scn_wrp , class
FROM sys.x$bh
WHERE obj= &&obj
AND dbablk= &&block
AND state!=0 ;
Enter value for obj: 75742
Enter value for block: 180
STATE MODE_HELD LE DBARFIL DBABLK CR_SCN_BAS CR_SCN_WRP CLASS
———- ———- — ————– ———- ———- ———- ———-
cr 0 00 1 75742 649314930 3015 1
cr 0 00 1 75742 648947873 3015 1
cr 0 00 1 75742 648926281 3015 1
cr 0 00 1 75742 648810300 3015 1
cr 0 00 1 75742 1177328436 3013 1
CR缓冲区的创建是一个特例,它并不需要获取全局缓存锁来保护CR缓冲区。如果频繁访问的对象上有长时间未提交的事物就可能会出现CR风暴。因此,明智的做法是把更新大量表数据的批处理安排在一个不太繁忙的时间段。
GC CR Grant 2-Way/Gc Current Grant 2-Way
如果被请求的块没有驻留在任何缓冲区中,就会遭遇gc cr grant 2-way 和 gc current grant 2-way等待事件。FG进程向LMS进程请求一个块,但块没有驻留在任何缓冲区。因此,LMS进程回复一条授权FG进程从磁盘读取的块的消息。FG进程从磁盘读取该块并继续后续的处理。
下面一行显示了为了访问file_id=4和lock_id=180数据块,FG进程接收到来自LMS进程的授权响应。下一行显示了,执行了一个从磁盘读取块的物理读。
nam=’gc cr grant 2-way’ ela= 402 p1=4 p2=180 p3=1 obj#=75742
nam=’db file sequential read’ ela= 553 file#=4 block#=180 blocks=1 obj#=75742
过多的此类等待意味着,要么缓冲区高速缓存太小,要么SQL语句的执行过分的刷新了缓冲区高速缓存。识别正在遭遇此类等待事件的SQL语句和对象,并优化这些SQL语句。
DRM功能的设计就是为了减少发生这类授权相关的等待事件。
GC CR Block Busy/GC Current Block Busy
繁忙事件(Busy events)表明,LMS执行了额外的工作去处理并发相关的问题。例如,要建立一个CR块,LMS进程可能要应用撤消记录(undo records),重构一个与查询的SCN一致的块。在把该块回传给FG过程时,LMS将标记块传输是否遇到gc cr block busy或gc current block busy等待事件,这取决于块传输的类型。
GC CR Block Congested/GC Current Block Congested
如果LMS进程在接收到请求后没有在1毫秒内处理该请求,那么LMS进程标记这个响应为:该块正遭遇拥堵相关的等待事件。堵塞相关的等待事件有很多原因,比如说,LMS进程被大量全局高速缓存的请求所淹没。LMS进程正遭遇CPU的调度延迟,LMS进程已经遇到了另一种资源耗尽(如内存)等。
通常情况下,LMS进程运行在实时CPU调度优先级,因此,CPU调度的延迟将是最小的。大量这类的等待此事件表明出现了全局缓存请求的突然飙升,且LMS进程无法快速处理这些请求。服务器内存匮乏也可能导致LMS进程的分页,影响全局缓存的性能。
您可以去检查为什么LMS进程不能够有效地处理请求。
ORA-00600[kcrf_resilver_log_1]异常恢复
朋友在win x64位上的ORACLE 11.2.0.1启动出现ORA-00600[kcrf_resilver_log_1],让我帮忙看看,通过分析主要是因为Unpblished Bug 9056657导致
数据库启动报错
数据库在open的时候报ORA-00600[kcrf_resilver_log_1]
SQL> alter database open; alter database open * 第 1 行出现错误: ORA-00600: 内部错误代码, 参数: [kcrf_resilver_log_1], [0x7FF61C56E30], [2], [], [], [], [], [], [], [], [], []
alert日志报错
Sat Mar 01 18:40:44 2014 alter database open Beginning crash recovery of 1 threads parallel recovery started with 3 processes Started redo scan Errors in file f:\app\administrator\diag\rdbms\orcl\orcl\trace\orcl_ora_6432.trc (incident=61360): ORA-00600: 内部错误代码, 参数: [kcrf_resilver_log_1], [0x7FF61C56E30], [2], [], [], [], [], [], [], [], [], [] Incident details in: f:\app\administrator\diag\rdbms\orcl\orcl\incident\incdir_61360\orcl_ora_6432_i61360.trc Aborting crash recovery due to error 600 Errors in file f:\app\administrator\diag\rdbms\orcl\orcl\trace\orcl_ora_6432.trc: ORA-00600: 内部错误代码, 参数: [kcrf_resilver_log_1], [0x7FF61C56E30], [2], [], [], [], [], [], [], [], [], [] Errors in file f:\app\administrator\diag\rdbms\orcl\orcl\trace\orcl_ora_6432.trc: ORA-00600: 内部错误代码, 参数: [kcrf_resilver_log_1], [0x7FF61C56E30], [2], [], [], [], [], [], [], [], [], [] ORA-600 signalled during: alter database open...
分先相关SCN
控制文件scn

控制文件中数据文件scn
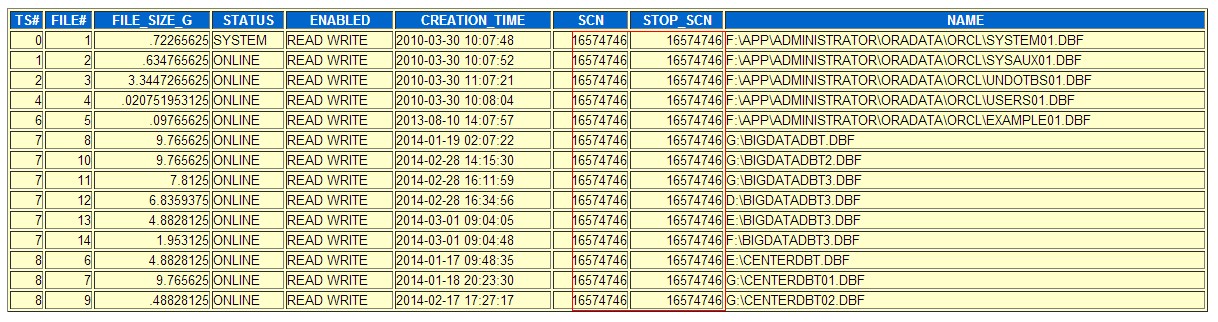
数据文件头scn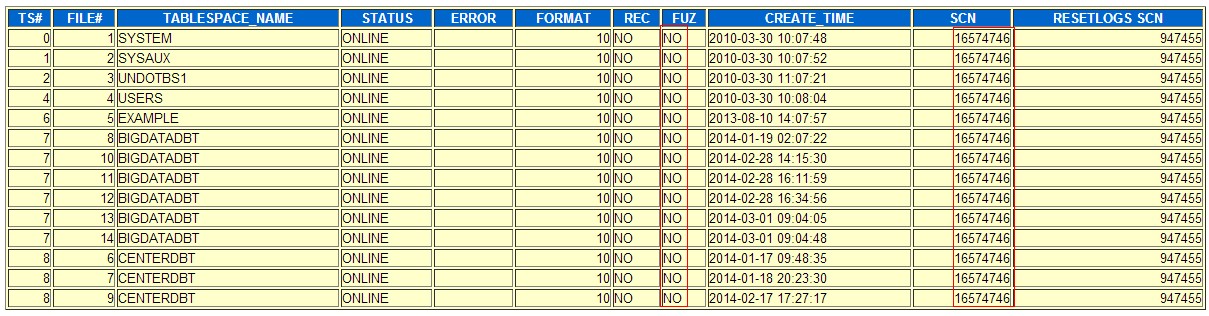
通过这里可以知道,数据文件头的scn,控制文件中关于数据文件的scn都表明数据库为正常关闭,且scn值为16574746,但是控制文件中记录数据库SCN的值为16551515,可以判断数据库因为某种原因导致控制文件中的部分scn记录异常.
处理方法
因为控制文件SCN异常,考虑直接重建控制文件或者using backup controlfile方式恢复
SQL> select group#,status,sequence# from v$log;
GROUP# STATUS SEQUENCE#
---------- ---------------- ----------
1 CURRENT 1510
3 ACTIVE 1509
2 ACTIVE 1508
GROUP# MEMBER
---------- --------------------------------------------------
3 F:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO03.LOG
2 F:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO02.LOG
1 F:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO01.LOG
SQL> recover database using backup controlfile until cancel;
ORA-00279: 更改 16574746 (在 03/01/2014 13:10:11 生成) 对于线程 1 是必需的
ORA-00289: 建议: F:\APP\ADMINISTRATOR\FLASH_RECOVERY_AREA\ORCL\ARCHIVELOG\2014_0
3_01\O1_MF_1_1510_%U_.ARC
ORA-00280: 更改 16574746 (用于线程 1) 在序列 #1510 中
指定日志: {<RET>=suggested | filename | AUTO | CANCEL}
F:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO01.LOG
已应用的日志。
完成介质恢复。
SQL> alter database open resetlogs;
数据库已更改。
在最近的同样的错误,但是没有如此的幸运具体参考:记录一次ORA-00600 [kcrf_resilver_log_1] 恢复过程
ORACLE REDO各种异常恢复
redo是oracle数据库比较核心文件,当redo异常之后,数据库无法正常启动,而且有丢失数据的风险,强烈建议条件允许redo多路镜像.redo文件异常的故障可以说是千奇百怪,但是总体上可以分为几类:
数据库归档/非归档模式下inactive redo异常
ORA-00316 ORA-00327
SQL> startup mount
ORACLE instance started.
Total System Global Area 260046848 bytes
Fixed Size 1266896 bytes
Variable Size 83888944 bytes
Database Buffers 167772160 bytes
Redo Buffers 7118848 bytes
Database mounted.
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 2 of thread 1, type in header is not log file
ORA-00312: online log 2 thread 1: '/u01/oracle/oradata/XFF/redo02.log'
SQL> col member for a40
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- -----------------------------------
1 15 3 665697 CURRENT /u01/oracle/oradata/XFF/redo03.log
1 14 2 645619 INACTIVE /u01/oracle/oradata/XFF/redo02.log
1 13 1 625540 INACTIVE /u01/oracle/oradata/XFF/redo01.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 2;
Database altered.
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00327: log 2 of thread 1, physical size less than needed
ORA-00312: online log 2 thread 1: '/u01/oracle/oradata/XFF/redo02.log'
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database open;
Database altered.
SQL> alter database add logfile group 2 ('/u01/oracle/oradata/XFF/redo02.log') size 50M reuse;
Database altered.
正常关闭数据库current redo异常
ORA-00316 ORA-01623
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- ----------------------------------
1 16 1 685918 CURRENT /u01/oracle/oradata/XFF/redo01.log
1 15 3 665697 INACTIVE /u01/oracle/oradata/XFF/redo03.log
1 0 2 0 UNUSED /u01/oracle/oradata/XFF/redo02.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type 0 in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> ALTER DATABASE drop logfile group 1;
ALTER DATABASE drop logfile group 1
*
ERROR at line 1:
ORA-01623: log 1 is current log for instance XFF (thread 1) - cannot drop
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> recover database until cancel;
Media recovery complete.
SQL> alter database open resetlogs;
Database altered.
数据库异常关闭current/active redo异常
ORA-00316 ORA-01624 ORA-01194
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type 0 in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- -----------------------------------
1 8 2 686310 CURRENT /u01/oracle/oradata/XFF/redo02.log
1 7 1 686294 ACTIVE /u01/oracle/oradata/XFF/redo01.log
1 6 3 686289 INACTIVE /u01/oracle/oradata/XFF/redo03.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance XFF (thread 1)
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> ALTER DATABASE drop logfile group 1;
ALTER DATABASE drop logfile group 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance XFF (thread 1)
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> recover database until cancel
ORA-00279: change 686294 generated at 04/20/2013 01:37:16 needed for thread 1
ORA-00289: suggestion : /u01/oracle/oracle/product/10.2.0/db_1/dbs/arch1_7_813202529.dbf
ORA-00280: change 686294 for thread 1 is in sequence #7
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
/u01/oracle/oradata/XFF/redo01.log
ORA-00308: cannot open archived log '/u01/oracle/oradata/XFF/redo01.log'
ORA-27047: unable to read the header block of file
Additional information: 2
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
cancel
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
ORA-01112: media recovery not started
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
SQL> alter system set "_allow_resetlogs_corruption"=true scope=spfile;
System altered.
SQL> shutdown immediate;
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 260046848 bytes
Fixed Size 1266896 bytes
Variable Size 83888944 bytes
Database Buffers 167772160 bytes
Redo Buffers 7118848 bytes
Database mounted.
SQL> recover database until cancel
ORA-00279: change 686294 generated at 04/20/2013 01:37:16 needed for thread 1
ORA-00289: suggestion : /u01/oracle/oracle/product/10.2.0/db_1/dbs/arch1_7_813202529.dbf
ORA-00280: change 686294 for thread 1 is in sequence #7
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
cancel
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
ORA-01112: media recovery not started
SQL> alter database open resetlogs;
Database altered.
在这样的情况下,数据库异常关闭,current/active redo异常,通过使用隐含参数可能可以侥幸的恢复数据库,但是也可能导致数据丢失.这里因为是模拟情况,无业务所以在很多较为繁忙的业务系统中,使用隐含参数resetlogs过程中可能还会遇到如下很多常见的错误,进一步增加了恢复难度
current/active redo异常后附带其他错误
ORA-600[2662]
Wed Dec 07 13:02:49 2011 SMON: enabling cache recovery Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_3388.trc (incident=216664): ORA-00600: 内部错误代码, 参数: [2662], [2], [1153862134], [2], [1153864845], [12582921], [], [] Incident details in: d:\app\administrator\diag\rdbms\hzyl\hzyl\incident\incdir_216664\hzyl_ora_3388_i216664.trc Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_3388.trc: ORA-00600: 内部错误代码, 参数: [2662], [2], [1153862134], [2], [1153864845], [12582921], [], [] Error 600 happened during db open, shutting down database USER (ospid: 3388): terminating the instance due to error 600
ORA-00600[4000]
Thu Feb 28 19:29:10 2013 SMON: enabling cache recovery Thu Feb 28 19:29:11 2013 Errors in file /u1/PROD/prodora/db/tech_st/10.2.0/admin/PROD_oracle/udump/prod_ora_20989.trc: ORA-00600: internal error code, arguments: [4000], [50], [], [], [], [], [], [] Thu Feb 28 19:29:13 2013 Incremental checkpoint up to RBA [0x1.3.0], current log tail at RBA [0x1.3.0] Thu Feb 28 19:29:13 2013 Errors in file /u1/PROD/prodora/db/tech_st/10.2.0/admin/PROD_oracle/udump/prod_ora_20989.trc: ORA-00704: bootstrap process failure ORA-00704: bootstrap process failure ORA-00600: internal error code, arguments: [4000], [50], [], [], [], [], [], []
ORA-00704 ORA-00604 ORA-01555
Fri May 4 21:04:21 2012 select ctime, mtime, stime from obj$ where obj# = :1 Fri May 4 21:04:21 2012 Errors in file /oracle/admin/standdb/udump/perfdb_ora_1286288.trc: ORA-00704: bootstrap process failure ORA-00704: bootstrap process failure ORA-00604: error occurred at recursive SQL level 1 ORA-01555: snapshot too old: rollback segment number 40 with name "_SYSSMU40$" too small Error 704 happened during db open, shutting down database USER: terminating instance due to error 704 Instance terminated by USER, pid = 1286288 ORA-1092 signalled during: alter database open resetlogs...
current/active redo异常还可能报如下错误
redo文件损坏报错
Started redo scan Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_2960.trc (incident=214262): ORA-00353: 日志损坏接近块 12014 更改 9743799889 时间 12/05/2011 09:21:11 ORA-00312: 联机日志 3 线程 1: 'R:\ORADATA\HZYL\REDO03.LOG' Incident details in: d:\app\administrator\diag\rdbms\hzyl\hzyl\incident\incdir_214262\hzyl_ora_2960_i214262.trc Aborting crash recovery due to error 368 Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_2960.trc: ORA-00368: 重做日志块中的校验和错误 ORA-00353: 日志损坏接近块 12014 更改 9743799889 时间 12/05/2011 09:21:11 ORA-00312: 联机日志 3 线程 1: 'R:\ORADATA\HZYL\REDO03.LOG' ORA-368 signalled during: ALTER DATABASE OPEN...
redo文件被其他实例占用报错
Wed May 16 17:03:11 2012 Started redo scan Wed May 16 17:03:11 2012 Errors in file /oracle/admin/odsdb/udump/odsdb1_ora_2040024.trc: ORA-00305: log 14 of thread 1 inconsistent; belongs to another database ORA-00312: online log 14 thread 1: '/dev/rods_redo1_2_2' ORA-00305: log 14 of thread 1 inconsistent; belongs to another database ORA-00312: online log 14 thread 1: '/dev/rods_redo1_2_1' ORA-305 signalled during: ALTER DATABASE OPEN...
存储整体异常
Mon Oct 17 09:35:09 2011 Errors in file /oracle/app/admin/orcl/bdump/orcl2_lgwr_348814.trc: ORA-00340: IO error processing online log 4 of thread 2 ORA-00345: redo log write error block 6732 count 2 ORA-00312: online log 4 thread 2: '/dev/rredo21' ORA-27063: number of bytes read/written is incorrect IBM AIX RISC System/6000 Error: 6: No such device or address Additional information: -1 Additional information: 1024 Mon Oct 17 09:35:09 2011 LGWR: terminating instance due to error 340
存储IO异常
Fri Feb 21 08:44:42 2014 Thread 1 advanced to log sequence 591 (LGWR switch) Current log# 1 seq# 591 mem# 0: J:\ORADATA\ORCL\REDO01.LOG Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_lgwr_10312.trc: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG'
使用_disable_logging参数
Sat May 14 23:16:49 2005 Errors in file d:\oracle\admin\rman\bdump\rman_arc0_736.trc: ORA-16038: log 3 sequence# 72 cannot be archived ORA-00354: corrupt redo log block header ORA-00312: online log 3 thread 1: 'D:\ORACLE\ORADATA\RMAN\REDO03.LOG'
如果你在使用这些思路进行恢复遇到突发情况不能自行解决,请联系我们,将为您提供专业数据库技术支持
Phone:17813235971 Q Q:107644445 E-Mail:dba@xifenfei.com
姊妹篇
undo异常总结和恢复思路
ORACLE丢失各种文件导致数据库不能OPEN恢复
记录一次ORA-00316 ORA-00312 redo异常恢复
正常运行的数据库报突然报ORA-00316: log 1 of thread 1, type 286 in header is not log file,异常终止
Fri Feb 21 08:44:42 2014 Thread 1 advanced to log sequence 591 (LGWR switch) Current log# 1 seq# 591 mem# 0: J:\ORADATA\ORCL\REDO01.LOG Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_lgwr_10312.trc: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG' Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_lgwr_10312.trc: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG' Fri Feb 21 15:31:20 2014 LGWR: terminating instance due to error 316 Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_j001_11328.trc: ORA-00316: log of thread , type in header is not log file Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_j000_14116.trc: ORA-00316: 日志 (用于线程 ) 标头中的类型 不是日志文件 Fri Feb 21 15:31:20 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_dbw1_8964.trc: ORA-00316: log of thread , type in header is not log file Fri Feb 21 15:31:22 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_dbw0_10592.trc: ORA-00316: log of thread , type in header is not log file ORA-27041: unable to open file OSD-04002: unable to open file O/S-Error: (OS 2) 系统找不到指定的文件。 ORA-27041: unable to open file OSD-04002: unable to open file O/S-Error: (OS 2) 系统找不到指定的文件。 Fri Feb 21 15:31:41 2014 Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_smon_11112.trc: ORA-00316: log of thread , type in header is not log file Fri Feb 21 15:31:41 2014 Instance terminated by LGWR, pid = 10312
数据库启动报ORA-00316错误
SQL> alter database open; alter database open * ERROR at line 1: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG'
alert日志信息,报ORA-00316 ORA-00312
Sun Feb 23 13:54:08 2014 Started redo scan Sun Feb 23 13:54:08 2014 Errors in file e:\oracle\product\10.2.0\admin\ora10g\udump\orcl_ora_5544.trc: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG' Sun Feb 23 13:54:08 2014 Aborting crash recovery due to error 316 Sun Feb 23 13:54:08 2014 Errors in file e:\oracle\product\10.2.0\admin\ora10g\udump\orcl_ora_5544.trc: ORA-00316: log 1 of thread 1, type 286 in header is not log file ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG' ORA-316 signalled during: alter database open...
通过dump redo header可以看出来redo header完全混乱了,里面很多数据文件内容在里面,初步估计系统或者硬件有问题(不稳定)导致该问题
LOG FILE #1: (name #3) J:\ORADATA\ORCL\REDO01.LOG Thread 1 redo log links: forward: 2 backward: 0 siz: 0x7d000 seq: 0x0000024f hws: 0x1 bsz: 512 nab: 0xffffffff flg: 0xa dup: 1 Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.4f4a1951 Low scn: 0x0000.4f4e5400 02/21/2014 08:44:42 Next scn: 0xffff.ffffffff 01/01/1988 00:00:00 FILE HEADER: Software vsn=4280360459=0xff211e0b, Compatibility Vsn=103886850=0x6313002 Db ID=842019892=0x32303434, Db Name='01a0001' Activation ID=1107558657=0x42040101 Control Seq=842019892=0x32303434, File size=808464688=0x30303130 File Number=2417, Blksiz=2013738803, File Type=286 UNKNOWN descrip:"00-440201|广东省xxxxxx研究院|00014402010037" thread: 767 nab: 0x534e4906 seq: 0xbcfebcbd hws: 0xffffffff eot: 55 dis: 66 reset logs count: 0x7545245 scn: 0x0101.1e097178 Low scn: 0x4537.2022002c 01/15/2022 20:59:37 Next scn: 0x3734.46463135 04/30/2017 17:34:49 Enabled scn: 0x4345.37333038 10/22/2015 02:04:16 Thread closed scn: 0x3939.43303143 08/25/2024 00:11:31 Log format vsn: 0x46343835 Disk cksum: 0x1d09 Calc cksum: 0x70ed Terminal Recovery Stop scn: 0x3734.35304141 Terminal Recovery Stamp 03/17/2014 19:59:48 Most recent redo scn: 0x3636.31303134 Largest LWN: 758788710 blocks Miscellaneous flags: 0x41444534 Thread internal enable indicator: thr: 263902399, seq: 808464496 scn: 0x3032.30343431
因为当前redo完全损坏,尝试不完全恢复并结合隐含参数(_allow_resetlogs_corruption)拉库,出现错误ORA-00704 ORA-00604 ORA-01555
Sun Feb 23 14:03:37 2014 SMON: enabling cache recovery Sun Feb 23 14:03:39 2014 ORA-01555 caused by SQL statement below (SQL ID: 4krwuz0ctqxdt, SCN: 0x0000.4f4e5405): Sun Feb 23 14:03:39 2014 select ctime, mtime, stime from obj$ where obj# = :1 Sun Feb 23 14:03:39 2014 Errors in file e:\oracle\product\10.2.0\admin\ora10g\udump\orcl_ora_5504.trc: ORA-00704: bootstrap process failure ORA-00704: bootstrap process failure ORA-00604: error occurred at recursive SQL level 1 ORA-01555: snapshot too old: rollback segment number 11 with name "_SYSSMU11$" too small Error 704 happened during db open, shutting down database USER: terminating instance due to error 704
通过修改scn,让数据库顺利open
