有网友在QQ上找我,说Oracle 7.3的数据库,因为redo异常咨询我是否可以恢复

检查数据库得到以下信息
SVRMGR> select * from v$version; BANNER ---------------------------------------------------------------- Oracle7 Workgroup Server Release 7.3.2.2.1 - Production Release PL/SQL Release 2.3.2.2.0 - Production CORE Version 3.5.2.0.0 - Production TNS for 32-bit Windows: Version 2.3.2.1.0 - Production NLSRTL Version 3.2.2.0.0 - Production 已选择 5 行
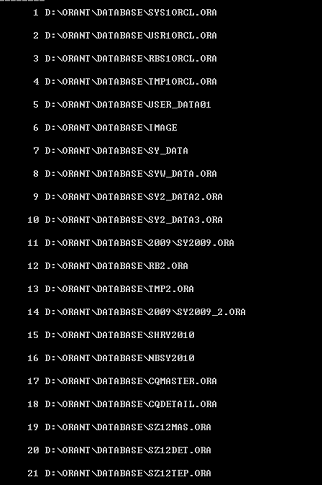
数据文件信息
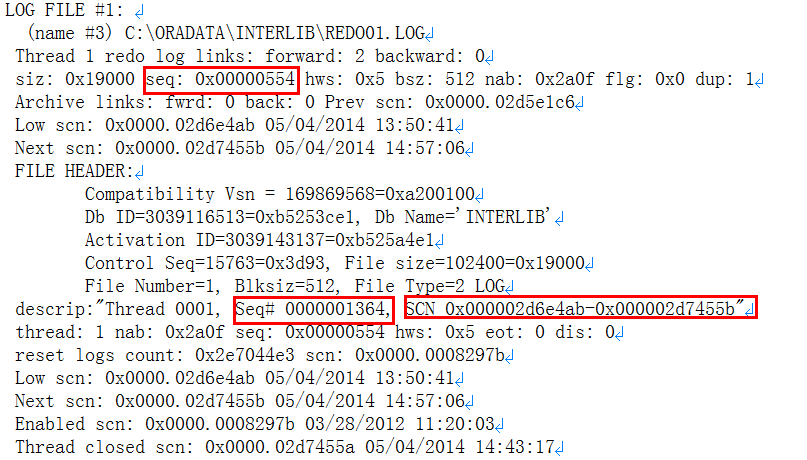
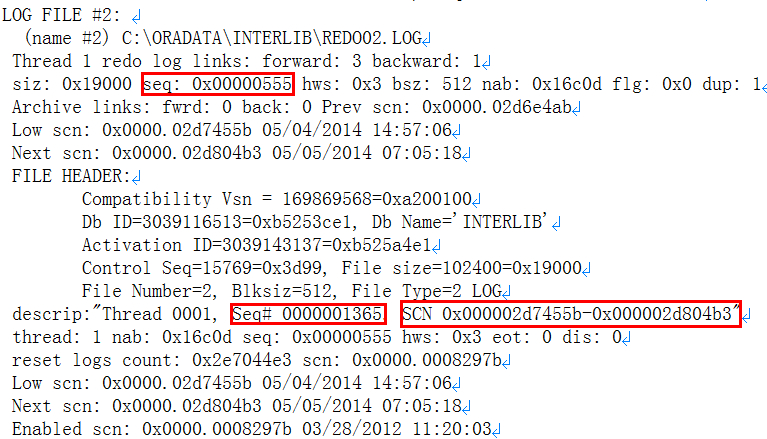
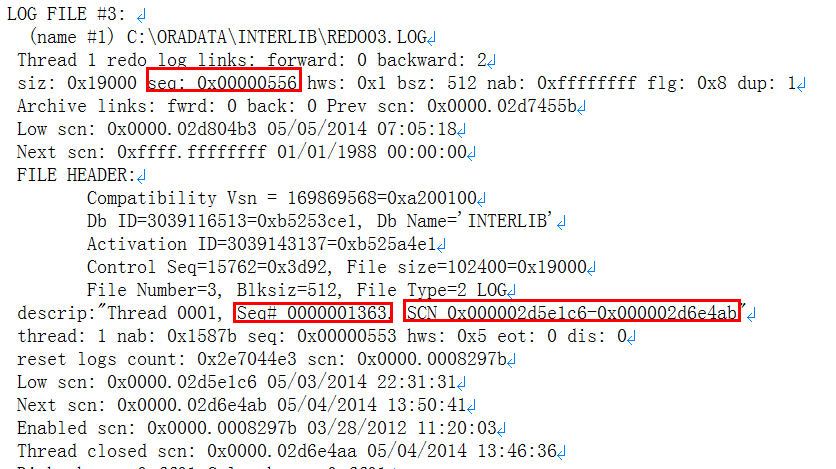
redo信息

跳过redo进行恢复,在resetlogs过程中报rbs表空间坏块,然后通过dul工具获得回滚段名称,然后使用隐含参数屏蔽掉
License high water mark = 2 Starting up ORACLE RDBMS Version: 7.3.2.2.1. System parameters with non-default values: processes = 800 shared_pool_size = 540000000 control_files = D:\ORANT\DATABASE\ctl1orcl.ora, D:\ORANT\DATABASE\ctl2orcl.ora compatible = 7.3.0.0.0 log_buffer = 327680 log_checkpoint_interval = 1000000 db_files = 40 db_file_simultaneous_writes= 1280 max_rollback_segments = 12800 _offline_rollback_segments= RB13, RB14, RB15, RB16, RB20 _corrupted_rollback_segments= RB13, RB14, RB15, RB16, RB20 sequence_cache_entries = 100 sequence_cache_hash_buckets= 100 remote_login_passwordfile= SHARED mts_servers = 0 mts_max_servers = 0 mts_max_dispatchers = 0 audit_trail = NONE sort_area_retained_size = 65536 sort_direct_writes = AUTO db_name = oracle open_cursors = 800 text_enable = TRUE snapshot_refresh_processes= 1 background_dump_dest = %RDBMS73%\trace user_dump_dest = %RDBMS73%\trace Mon Jun 16 16:46:57 2014 PMON started Mon Jun 16 16:46:57 2014 DBWR started Mon Jun 16 16:46:57 2014 LGWR started Mon Jun 16 16:46:57 2014 RECO started Mon Jun 16 16:46:57 2014 SNP0 started Mon Jun 16 16:46:57 2014 alter database mount exclusive Mon Jun 16 16:46:58 2014 Successful mount of redo thread 1. Mon Jun 16 16:46:58 2014 Completed: alter database mount exclusive Mon Jun 16 16:48:15 2014 alter database open Mon Jun 16 16:48:16 2014 Beginning crash recovery of 1 threads Crash recovery completed successfully Mon Jun 16 16:48:17 2014 Thread 1 advanced to log sequence 9 Current log# 1 seq# 9 mem# 0: D:\ORANT\DATABASE\LOG2ORCL.ORA Thread 1 opened at log sequence 9 Current log# 1 seq# 9 mem# 0: D:\ORANT\DATABASE\LOG2ORCL.ORA Successful open of redo thread 1. Mon Jun 16 16:48:18 2014 SMON: enabling cache recovery Mon Jun 16 16:48:19 2014 Completed: alter database open Mon Jun 16 16:48:20 2014 SMON: enabling tx recovery SMON: about to recover undo segment 14 SMON: mark undo segment 14 as needs recovery SMON: about to recover undo segment 15 SMON: mark undo segment 15 as needs recovery SMON: about to recover undo segment 16 SMON: mark undo segment 16 as needs recovery SMON: about to recover undo segment 17 SMON: mark undo segment 17 as needs recovery SMON: about to recover undo segment 18 SMON: mark undo segment 18 as needs recovery Mon Jun 16 16:48:20 2014 Errors in file D:\ORANT\RDBMS73\trace\orclSMON.TRC: ORA-00600: internal error code, arguments: [4306], [21], [2], [], [], [], [], []
数据库在启动过程中出现ORA-00600[4306],导致smon异常。该错误是因为在数据库open过程中smon会清理临时段从而出现该错误,通过设置event跳过,数据库算整体打开,不过在恢复过程中还遇到了
Mon Jun 16 17:53:10 2014 Errors in file D:\ORANT\RDBMS73\trace\orclDBWR.TRC: ORA-00600: internal error code, arguments: [3600], [3], [14], [], [], [], [], [] Mon Jun 16 18:05:12 2014 Errors in file D:\ORANT\RDBMS73\trace\ORA06880.TRC: ORA-01578: ORACLE数据块有错(文件号12, 块号46644) ORA-01110: 文件'12'没有联机 ORA-00600: 内部错误码, 变元: [4194], [18], [5], [], [], [] ORA-00600: 内部错误码, 变元: [4194], [18], [5], [], [], []
ORA-00600[3600]是因为在offline 回滚段所在表空间锁出现的问题
ORA-00600[4194]是因为回滚段所在的表空间数据文件出现坏块所导致